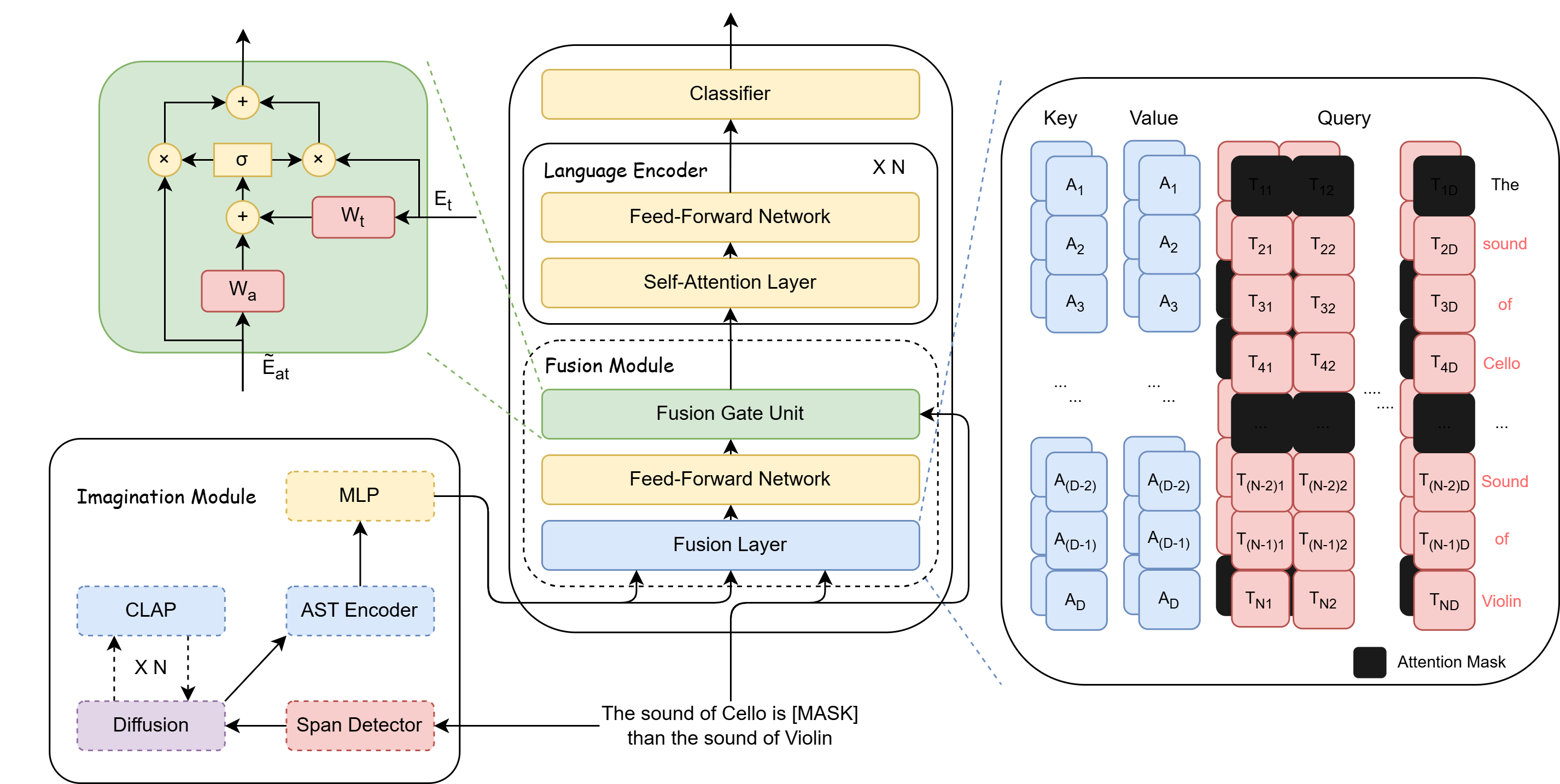
ITH Case Study
Sentence: Rattle is the sound a [MASK] makes.
Answer: Snake
BERT: Dog
ITH: Snake
Sentence: The sound of chirping in the fall is often associated with a [MASK].
Answer: Cricket
BERT: Bird
ITH: Cricket
DKI Case Study - Part 1
Sentence: The sound of guitar is [MASK] than the sound of sopranissimo saxophone.
Answer: Lower
w/o DKI: Higher
ITH: Lower
Guitar
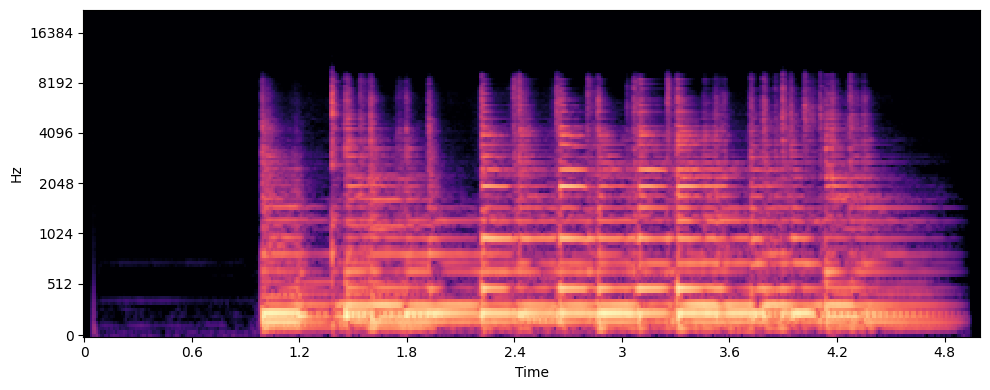
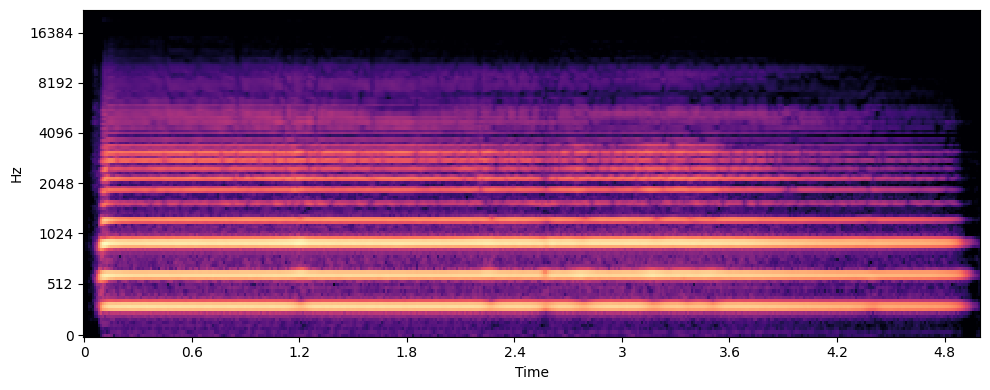
Sopranissimo Saxophone
Sentence
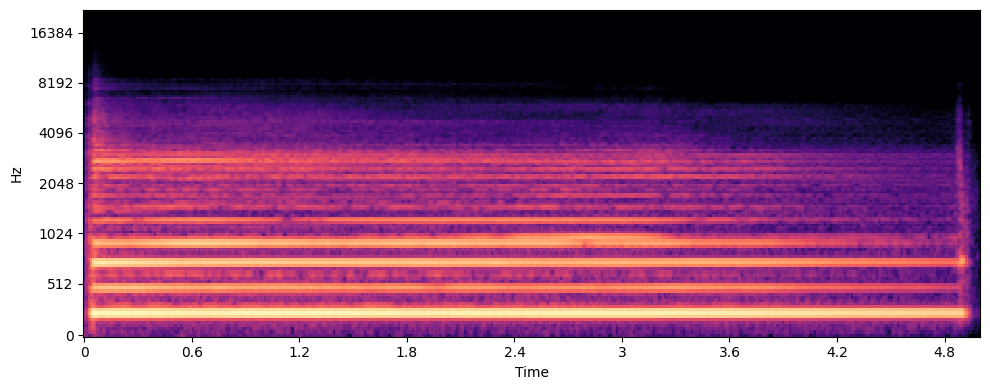
DKI Case Study - Part 2
Sentence: The sound of alto trombone is [MASK] than the sound of sopranino trombone.
Answer: Lower
w/o DKI: Higher
ITH: Lower
Alto Trombone
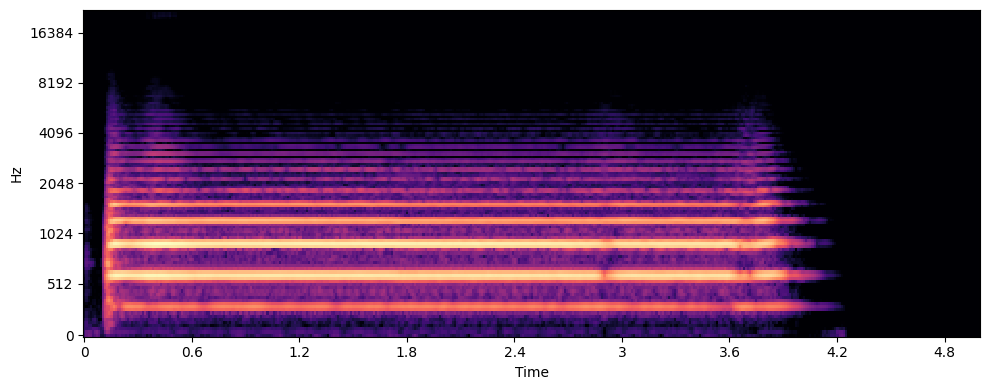
Sopranino Trombone
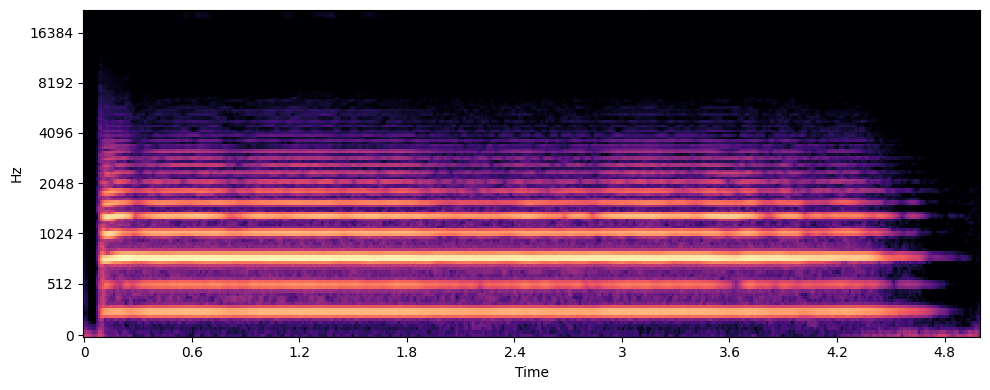
Sentence
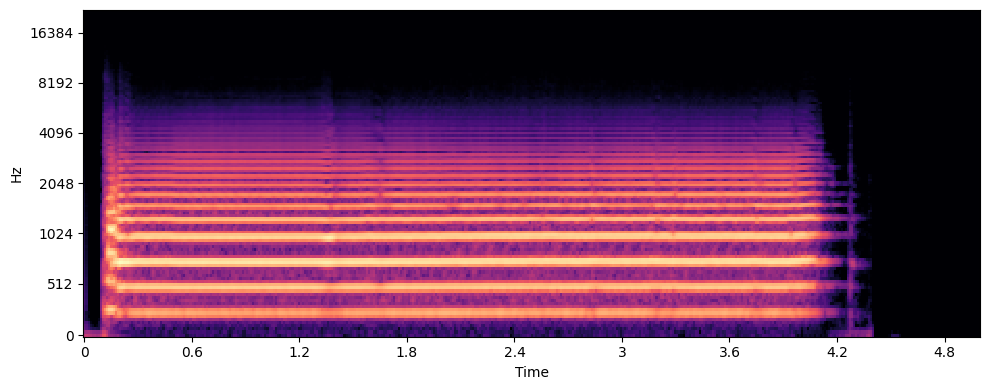
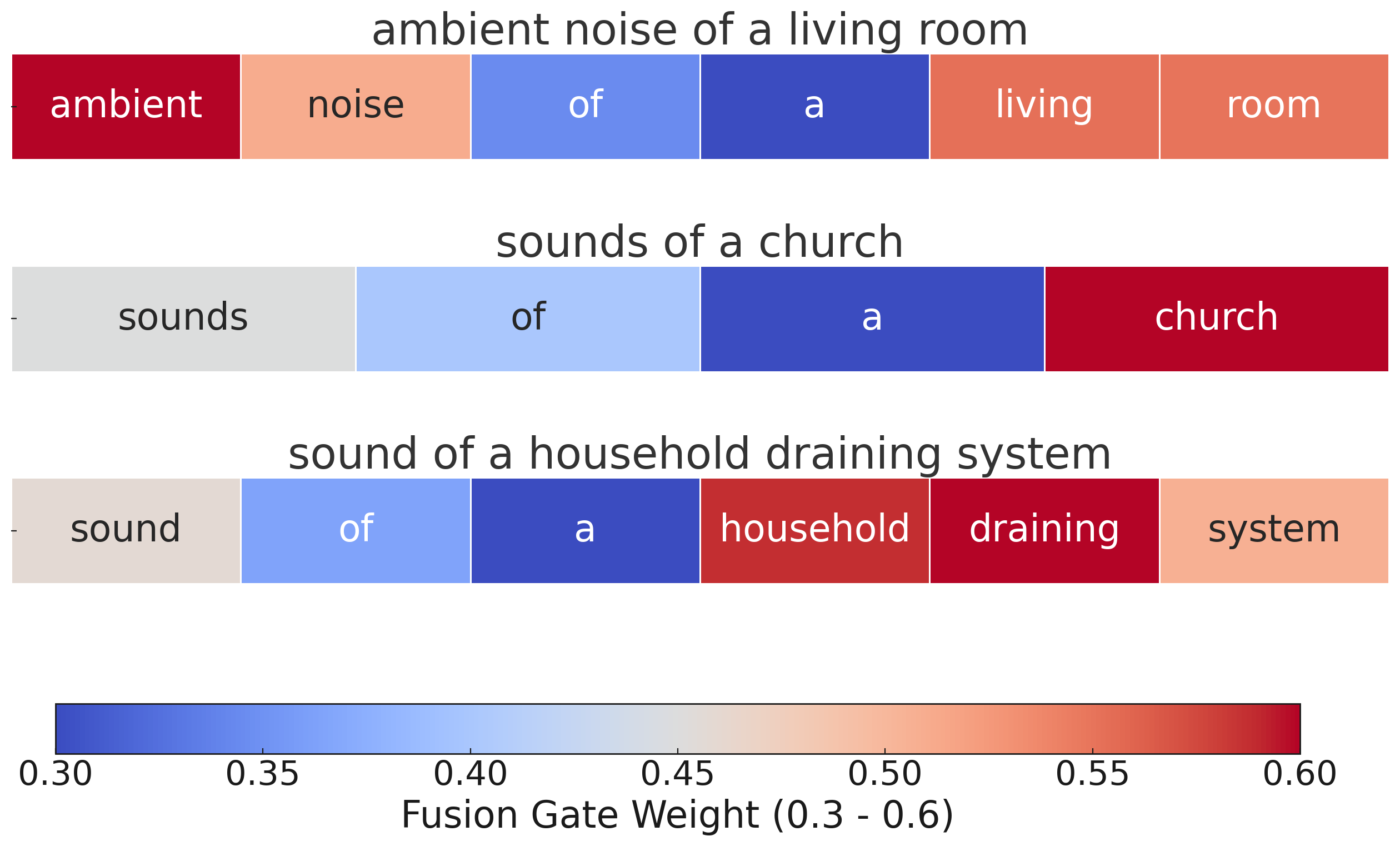
Fusion Gate Case Study